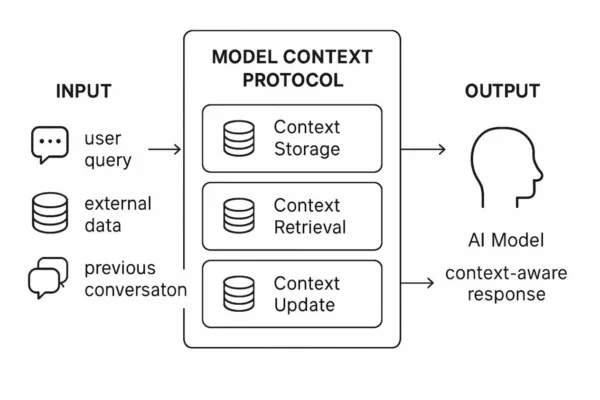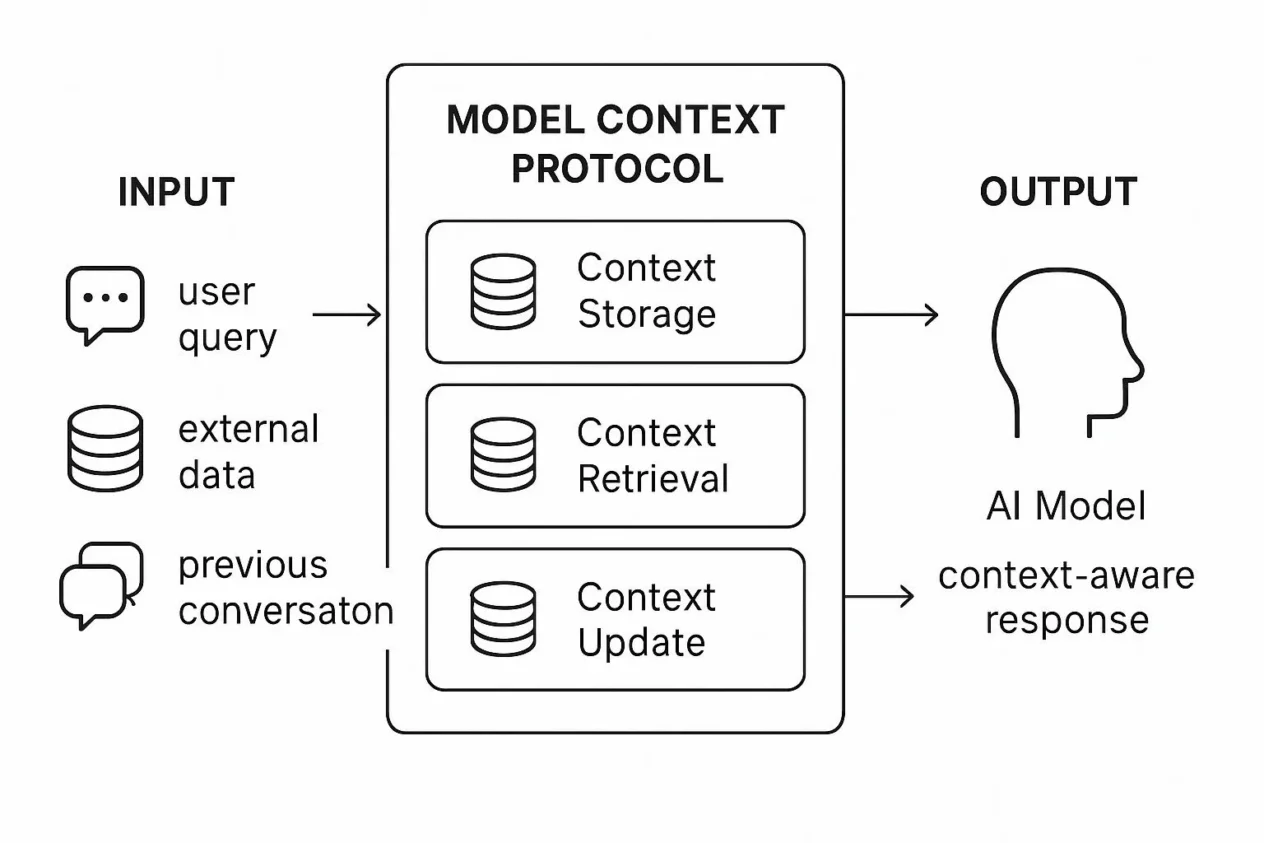
Traditional software security focuses on code, configuration, and infrastructure. Agentic AI security introduces a fundamentally different challenge: systems that can interpret goals, plan multi-step actions, select and invoke tools, and make decisions with limited human oversight. That shift transforms the attack surface from static code paths into dynamic execution chains where prompting, context, memory, and tool design all become security-relevant. In this guide, we examine the seven core attack scenarios facing autonomous AI systems and the engineering controls needed to keep them safe.
Thank you for reading this post, don't forget to subscribe!
Why Agentic AI Security Creates a Fundamentally New Attack Surface
Specifically, normal chatbots generate text. Agentic systems generate actions. The difference matters because once a model can reason over context, choose tools, and execute multi-step plans, security failures are no longer limited to unsafe output. They can include unauthorized file operations, credential misuse, data exfiltration, cloud resource changes, and workflow manipulation. Therefore, the security model must account for goal interpretation, planning loops, tool invocation, identity scope, and persistent state – not just input validation and output filtering.
Furthermore, OWASP recognized this shift by releasing a dedicated Top 10 for Agentic Applications in 2026, identifying risks like goal hijack, tool misuse, identity and privilege abuse, memory poisoning, and agentic supply chain vulnerabilities as the most critical threats facing autonomous AI. NIST Generative AI Profile for the AI RMF reinforces this with governance requirements that go beyond traditional software assurance. Consequently, organizations deploying agentic systems must treat security as a first-class architectural concern, not an afterthought bolted onto a chatbot wrapper.
Goal Hijack – A Core Agentic AI Security Challenge
Goal hijack occurs when hostile context, hidden instructions, or poisoned retrieved content causes an agent to reinterpret or subordinate its intended task. This is more dangerous than classic prompt injection because the agent does not merely produce a bad response – it may execute a diverted multi-step plan that affects real systems. The attack works by exploiting the boundary between trusted policy instructions and untrusted user or retrieved content.
Indeed, goal hijack is amplified by retrieval-augmented generation. When an agent pulls context from documents, web pages, or knowledge bases, any poisoned content can silently reshape planning priorities without changing the visible user request. Specifically, defenders must ensure that trusted system policies remain dominant over retrieved content, that context boundaries are clearly labeled, and that plan review mechanisms can detect goal drift before execution begins.
Tool Misuse – A Critical Agentic AI Security Risk
In practice, tool access is what transforms an AI model from a content generator into an operational system. It is also where agentic AI becomes materially risky. An agent may select the wrong tool, invoke a correct tool with unsafe parameters, chain tools in a harmful sequence, or use a legitimate tool for an unintended purpose. The gap between what the model intends and what the tool actually does can create direct business impact.
As a result, tool output often re-enters the planning loop as trusted input. If an agent calls a search tool and receives manipulated results, those results may shape subsequent decisions and actions. Therefore, effective agentic security requires strict tool schema validation, approval gates for state-changing operations, clear separation between read-only and destructive capabilities, and output sanitization before tool results influence future planning.
Identity and Privilege Abuse in Agentic AI Security
In particular, agents typically inherit credentials, delegated scopes, service accounts, or user context to perform their tasks. When that identity scope is too broad, poorly segmented, or insufficiently observable, the agent can operate far beyond what its specific task requires. A single over-privileged agent becomes a high-value target because compromising its context or redirecting its planning can immediately escalate to full account or tenant access.
As such, long-lived tokens attached to autonomous workflows create persistent risk. Unlike interactive sessions that expire, agentic workflows may run for hours or days with the same credentials. Therefore, defenders must enforce per-tool least privilege, use short-lived credentials with automatic rotation, maintain identity transparency in audit logs, and ensure that credential scope matches the minimum required for each specific agent capability.
Memory Poisoning – A Hidden Agentic AI Security Threat
Importantly, one of the most insidious risks in agentic AI security is memory poisoning. When systems store conversation summaries, user preferences, task history, or retrieved knowledge for future use, a single successful manipulation can persist across sessions and influence future agent behavior. Unlike a traditional app where restarting the process clears state, poisoned agent memory creates durable attack leverage.
Equally, multi-agent systems can propagate poisoned state across agent boundaries. If one agent stores manipulated facts in shared memory, every other agent that retrieves from that store inherits the distortion. Consequently, memory stores must have strong write controls, trusted-source prioritization, expiration rules, and review paths that allow operators to inspect and purge compromised state before it cascades through the system.
Related Resources for Deeper Learning
Notably, agentic AI security intersects with several other critical security domains that we have covered in depth. For a comprehensive understanding of how AI model connectors create supply chain risk, explore our analysis of MCP security and pentesting for the Model Context Protocol. Additionally, to understand how API authorization flaws parallel the tool misuse patterns in agentic systems, read our guide on API security authorization flaws behind modern breaches.
Furthermore, the identity and privilege abuse risks in agentic AI mirror the identity-based attacks we cover in our identity as the new perimeter analysis. Supply chain risks in the agentic ecosystem also connect directly to our guide on software supply chain security, which covers dependency risk, build pipeline trust, and artifact integrity. These interconnected domains demonstrate why a holistic security approach is essential as AI systems become more autonomous.
Agentic AI Security: The New Attack Surface in Autonomous Systems
A practical technical guide to agentic AI security, covering goal hijack, tool misuse, identity and privilege abuse, memory and context poisoning, multi-agent trust, agentic supply chain risk, and the guardrails needed when AI systems can plan, decide, and act.
Table of Contents
- First, why agentic AI changes the threat model
- Second, agentic AI security visuals
- Third, why agentic systems create new risk
- Next, core attack scenarios
- Then, real-world examples and public signals
- Furthermore, tool-assisted validation
- Additionally, severity matrix
- Moreover, common implementation mistakes
- Also, defensive hardening checklist
- Finally, pentester quick checklist
- In conclusion, final conclusion
Why agentic AI security changes the threat model
Historically, traditional software usually follows a narrow control path. A user provides input, a system executes pre-defined logic, and the outcome is bounded by code written in advance. Agentic AI changes that model because the system can interpret a goal, plan intermediate steps, decide which tools to use, retrieve context, adapt to new information, and continue acting with limited or delayed human involvement. That is a real security shift, not just a user-experience change.
However, the security problem is not only that an LLM may generate unsafe text. The larger problem is that the model can become part of an execution loop. Once an agent is allowed to reason over context and invoke tools that affect files, code, tickets, cloud resources, identity providers, or customer systems, mistakes in prompting, authorization, context boundaries, or tool design can create operational consequences. The attack surface now includes goals, memories, tool descriptions, planning loops, environment state, role boundaries, and action approval logic.
This is exactly why OWASP released a dedicated Top 10 for Agentic Applications for 2026, describing it as a globally peer-reviewed framework for the most critical risks facing autonomous and agentic AI systems. Similarly, NIST’s Generative AI Profile for the AI RMF also reinforces that generative systems introduce novel risk patterns that require governance, measurement, monitoring, and operational controls beyond normal software assurance. (genai.owasp.org)
Consequently, the system does not only answer. It can choose, chain, and act across multiple steps.
Therefore, security must now cover goal interpretation, tool use, context trust, and the consequences of autonomous execution.
Ultimately, find where the agent can be redirected, over-privileged, over-trusting, or insufficiently constrained before those paths become real actions.
Agentic AI security visuals
Specifically, the diagrams below show how an agentic system differs from a normal chat interface. The main risk comes from the movement from text generation to tool-backed execution under dynamic planning.
Agentic AI trust and execution path
In essence, the key lesson is that in agentic AI security, untrusted input can influence planning, planning can influence action, and action can change the state that future planning depends on.
Goal hijack path
Notably, this shows why hidden instructions and hostile context can redirect agent intent without changing the top-level user request visibly.
Tool misuse path
As noted, tool access turns model misalignment from a content problem into an operational problem.
Identity and privilege risk
Clearly, if the agent inherits more identity or more scopes than needed, mistakes quickly become privilege abuse.
Memory and context poisoning
Crucially, this shows why persistent memory and retrieval stores become security-relevant, not just product features.
Why agentic systems create new risk
Primarily, agentic systems create new risk because they combine uncertainty with authority. A normal automation tool executes a bounded workflow. An agent interprets the goal, judges what matters, chooses a next step, and may invoke tools repeatedly in a loop. That means the system is partly defined by configuration and partly defined by live context. Security teams cannot treat this as a normal API problem or a normal chatbot problem. It is both, plus decision logic on top.
Furthermore, a second reason is that agentic systems often accumulate hidden trust. They may have memory, cached credentials, delegated access, internal knowledge connectors, code execution tools, file tools, browser tools, or ticketing actions. Even if each component seems manageable, the combined system can become over-privileged or under-observed. A small prompt or context weakness may therefore trigger a larger operational effect than expected.
Indeed, OWASP’s 2026 agentic framework makes this explicit through risk categories such as Agent Goal Hijack, Tool Misuse, Identity & Privilege Abuse, Agentic Supply Chain Vulnerabilities, and Unexpected Agent Behavior. These categories show that the security conversation has already moved beyond classic prompt injection into broader issues of autonomy, access, and control. (genai.owasp.org)
Core agentic AI security attack scenarios every assessment should cover
1. Goal hijack and instruction redirection
High RiskEssentially, goal hijack occurs when hostile context or hidden instructions cause the agent to reinterpret or subordinate the original goal. This is more severe than ordinary prompt injection because the output may influence a multi-step plan rather than a single answer.
Security scenarios
- For instance, retrieved content silently overriding task priorities
- Alarmingly, hidden instructions embedded in documents or web content
- Similarly, system prompt intent eroded by tool-returned text
- Crucially, long-horizon task planning influenced by poisoned context
Testing focus
- First, ensure separation between trusted and untrusted instructions
- Second, enforce context labeling and boundary enforcement
- Third, review plan review under hostile retrieved content
- Finally, ensure reconciliation of goal, policy, and retrieved data
2. Tool misuse and unsafe action selection
Operational RiskIn reality, tool misuse is where agentic AI security becomes materially risky. The agent may choose the wrong tool, invoke a correct tool with unsafe parameters, chain tools in a harmful order, or use a legitimate tool for an unintended purpose.
Security scenarios
- Notably, deletion, modification, or transfer operations triggered too easily
- Furthermore, tool output reused as trusted planning input without validation
- Alarmingly, dangerous actions not gated by approval or policy
- Consequently, multi-tool chain creating emergent harmful behavior
Testing focus
- Specifically, tool schema strictness and argument validation
- Moreover, approval gates for state-changing actions
- In addition, policy checks before and after tool execution
- Ultimately, tool output trust model and sanitization
3. Identity and privilege abuse
Access RiskTypically, agents often inherit credentials, delegated scopes, service accounts, or user context. If that identity scope is too broad, poorly segmented, or insufficiently observable, the agent can operate far beyond what its task requires.
Security scenarios
- Chiefly, agent using broad service credentials instead of least privilege
- Alarmingly, cross-tenant access through shared context or tokens
- Notably, long-lived tokens attached to autonomous workflows
- Crucially, identity chaining across tools without revalidation
Testing focus
- First, verify per-tool least privilege design
- Second, check delegation boundaries and token scope
- Third, test credential lifetime and revocation readiness
- Finally, ensure identity transparency in logs and approvals
4. Memory poisoning and context contamination
Persistence RiskAlarmingly, persistent memory and retrieved context can make one bad interaction durable. If the system stores unsafe summaries, poisoned user facts, manipulative instructions, or misleading task history, future planning may inherit those distortions.
Security scenarios
- For example, long-term memory storing attacker-influenced state
- Similarly, context windows mixing trusted rules and untrusted notes poorly
- Alarmingly, knowledge stores returning poisoned or misleading planning input
- Crucially, session-to-session contamination of agent behavior
Testing focus
- First, implement memory write controls and moderation
- Second, enforce trusted-source prioritization in retrieval
- Third, ensure reviewability and expiration of persistent memory
- Finally, verify cross-session contamination prevention
5. Agentic supply chain and connector risk
Trust RiskMoreover, agentic systems depend on models, orchestration layers, plugins, MCP-style connectors, retrieval tools, prompts, hosted tools, and often external SaaS APIs. That means the supply chain is not only the model provider; it is the whole execution ecosystem.
Security scenarios
- For instance, compromised or weak third-party tools influencing behavior
- Alarmingly, connector trust assumptions wider than intended
- Notably, prompt, plugin, or orchestration drift changing runtime security
- Crucially, hidden capability expansion through updated tool availability
Testing focus
- First, maintain tool and connector inventory
- Second, perform runtime capability review and change management
- Third, enforce third-party trust and isolation boundaries
- Finally, verify provenance and update governance of agent components
6. Unexpected agent behavior and runaway autonomy
Control RiskSignificantly, even without malicious prompting, autonomous systems can behave unexpectedly because of planning instability, tool feedback loops, or underspecified stopping conditions. This makes safety controls and bounded autonomy essential.
Security scenarios
- Chiefly, loops of repeated calls or escalating actions
- Alarmingly, self-reinforcing plans that drift away from policy
- Notably, over-optimization toward a partial goal
- Crucially, failure to stop when context becomes uncertain or conflicting
Testing focus
- First, enforce execution budgets and step limits
- Second, implement kill switches and supervisory interrupts
- Third, verify confidence-aware fallback behavior
- Finally, test action review under ambiguous or conflicting goals
7. Multi-agent trust and coordination failure
Distributed RiskAdditionally, multi-agent systems introduce coordination complexity. Agents may trust summaries, outputs, or delegated tasks from other agents without adequate validation, creating cascaded failures and widening the blast radius of one poisoned step.
Security scenarios
- Chiefly, one compromised sub-agent influencing the whole workflow
- Alarmingly, delegated tasks accepted without verification
- Notably, shared memory or context stores propagating poisoned state
- Crucially, role confusion between coordinator and executor agents
Testing focus
- First, define inter-agent trust boundaries
- Second, enforce validation of delegated outputs
- Third, verify shared state hygiene and rollback controls
- Finally, ensure role clarity and scoped authority for each agent
Real-world agentic AI security examples and public signals
Admittedly, agentic AI is still early, but public frameworks and early disclosures already show the shape of the problem. This topic is in demand because the risks are moving from theory into practical design concerns.
Notably, OWASP’s Top 10 for Agentic Applications 2026 identifies the most critical risks facing autonomous and agentic AI systems, which is a strong signal that the security community now sees agentic risk as distinct from ordinary LLM risk. (genai.owasp.org)
Furthermore, OWASP’s own announcement ties categories like goal hijack, tool misuse, and identity abuse to public examples such as EchoLeak and Amazon Q related discussions, showing that these categories are not purely hypothetical. (genai.owasp.org)
NIST’s Generative AI Profile for the AI RMF emphasizes governance, measurement, monitoring, and handling of novel GenAI-specific risks, which aligns directly with the operational controls agentic systems need. (nvlpubs.nist.gov)
What these signals mean for defenders
- Crucially, agentic security should not be treated as “prompt injection plus a little more.”
- Furthermore, tool access, memory, planning loops, and identity scope now deserve first-class security design.
- Importantly, organizations need governance for agent capabilities before they need broad agent deployment.
- Ultimately, the security model must assume that reasoning and execution can influence each other recursively.
Tool-assisted validation
Generally, agentic AI assessments are strongest when they combine prompt and context testing with runtime telemetry review, tool permission analysis, approval-path validation, and memory-state inspection. The question is not only “what did the model say?” It is “what did the system decide, what tools did it use, and what state did it change?”
| Validation area | Purpose | Safe review example | Third, what to look for |
|---|---|---|---|
| First, prompt and context testing | Second, assess goal hijack resistance | Review how the system handles hostile retrieved content and conflicting instructions in a controlled test environment |
Finally, whether trusted policies remain dominant under manipulated context. |
| First, tool schema and permission review | Second, reduce unsafe action capability | Inspect tool definitions, parameter validation, and state-changing action approval paths |
Finally, over-broad arguments, missing constraints, or risky unaudited tools. |
| First, identity and token review | Second, validate least privilege | Map which credentials, roles, or delegated scopes each agent can actually use |
Finally, shared credentials, long-lived tokens, and privilege scope larger than the task. |
| First, memory and retrieval testing | Second, check persistence and poisoning risk | Inspect memory write conditions, retrieval ranking, and whether untrusted state can persist across tasks |
Notably, poisoned memory, contaminated context, or no expiration and review logic. |
| Furthermore, runtime telemetry and audit | Specifically, see what the agent really did | Review goal, plan, tool calls, outputs, approvals, and resulting system changes together |
Crucially, blind spots between reasoning, execution, and post-action monitoring. |
Severity matrix for agentic AI security failures
In contrast, agentic failures differ from classic app failures because a small control weakness can amplify through planning loops and tool chains. The matrix below helps prioritize the controls with the highest leverage.
| Scenario | Likelihood | Potential severity | Why it matters | Priority |
|---|---|---|---|---|
| First, goal hijack through hostile context | High | High | Specifically, can change planning direction before any tool is used, which affects the entire workflow. | Immediate |
| Second, tool misuse with state-changing impact | Notably, medium to high | Critical | Specifically, turns model error or manipulation into direct business or system action. | Immediate |
| Third, identity and privilege abuse | Medium | Critical | Specifically, one over-privileged agent can act far beyond the user’s intended task scope. | Immediate |
| Fourth, memory poisoning and context contamination | Medium | High | Alarmingly, can make one successful manipulation persistent across later tasks and sessions. | High |
| Fifth, agentic supply chain and connector drift | Medium | High | Crucially, silent capability expansion or tool compromise changes the runtime attack surface quickly. | High |
| Unexpected or runaway autonomy | Medium | High | Execution loops and unstable plans can create harmful outcomes even without direct malicious prompting. | High |
Common implementation mistakes
Unfortunately, agentic systems often fail not because one control is entirely missing, but because the engineering team underestimates how many trust boundaries now exist inside a single “AI feature.”
Frequent mistakes seen in early agentic deployments
- First, avoid treating all retrieved context as equally trustworthy.
- Second, avoid giving agents broader tool access than the task requires.
- Third, avoid failing to distinguish between observation tools and state-changing tools.
- Fourth, avoid letting tool output re-enter the planning loop without validation.
- Fifth, avoid using long-lived or shared credentials for convenience.
- Sixth, avoid adding memory without strong write controls, expiration rules, or review paths.
- Seventh, avoid measuring safety at the output layer only, not at the action and state-change layer.
- Finally, avoid deploying multi-agent systems before clarifying which agent is allowed to trust which other agent.
Defensive hardening checklist
Ultimately, strong agentic AI security comes from constrained autonomy, least privilege, context boundaries, and good observability. The system should be able to reason, but it should not be able to do everything it can imagine.
- First, separate trusted policy instructions from untrusted retrieved or user-provided content clearly.
- Second, constrain tool access tightly and differentiate read-only from state-changing capabilities.
- Third, require stronger approval or human review for high-impact actions.
- Fourth, use least-privilege identity and short-lived credentials for agents and connectors.
- Fifth, moderate and review memory writes, and expire or isolate persistent state thoughtfully.
- Sixth, limit planning depth, step count, and execution budget to reduce runaway behavior.
- Seventh, log goals, plans, tool calls, approvals, outputs, and state changes as one coherent audit trail.
- Eighth, review connectors, prompts, orchestration layers, and external tools as supply chain trust decisions.
- Ninth, test the system against hostile context, tool feedback manipulation, and multi-agent trust confusion before production.
Pentester quick checklist
- Finally, map the agent’s goals, planning loop, tool set, memory stores, and connectors end to end.
- First, test whether hostile context can override or distort the intended goal.
- Second, review whether tool arguments, outputs, and state-changing actions are strongly bounded.
- Third, inspect identity scope, token lifetime, and delegated access for each agent capability.
- Fourth, check memory write controls, retrieval ranking, and cross-session contamination risk.
- Fifth, validate that high-impact actions require stronger gating than low-risk actions.
- Sixth, assess whether the runtime audit trail can reconstruct goal, plan, action, and impact clearly.
- Finally, review whether multi-agent coordination creates hidden trust or hidden privilege transfer.
Final agentic AI security conclusion
In summary, agentic AI security is the new attack surface because it combines reasoning, memory, tools, and autonomy in one execution chain. That chain can create productivity gains, but it also creates a new class of security problem: the system can be influenced, can decide, and can act.
For this reason, agentic security deserves to be treated as its own discipline. The risks are not only about prompt injection anymore. They include goal hijack, tool misuse, identity and privilege abuse, memory poisoning, multi-agent trust failure, and supply chain drift in the orchestration ecosystem. OWASP’s 2026 agentic framework and NIST’s GenAI risk guidance both point in the same direction: organizations need stronger governance, clearer trust boundaries, and safer operational defaults before they scale autonomous AI use. (genai.owasp.org)
Ultimately, for builders, the right question is no longer “Can the model do this?” The better question is “Should the system be allowed to do this, under this identity, with this context, using these tools, and with this level of human oversight?” That is the core of agentic AI security.
Continue Reading
Stay ahead of evolving security threats with our in-depth technical analyses. Each guide provides practical insights for defenders and engineers protecting modern systems:
- MCP Security and Pentesting: Model Context Protocol Deep Dive – Securing AI tool integration through the Model Context Protocol
- API Security: Authorization Flaws Behind Modern Breaches – BOLA, BFLA, shadow APIs, and mass assignment in real-world breaches
- Identity Security: The New Perimeter of Modern Attacks – How MFA bypass, OAuth consent phishing, and token replay exploit identity trust
- Software Supply Chain Security: Risks in Dependencies, Builds and Secrets – Dependency risk, secrets exposure, CI/CD trust, and SBOM visibility
- Ransomware 2016 to 2026: What Defenders Are Still Missing – Evolution of ransomware tactics and defensive strategy gaps